Résumé de la session
Introduction aux mégadonnées en sciences sociales
Structure du cours

Principe fondamental : la reconversion
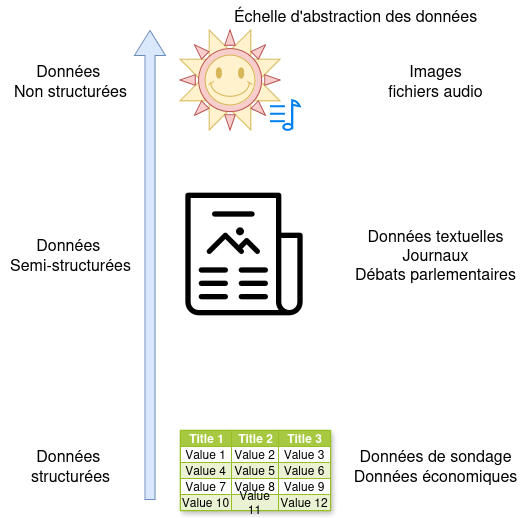
Notre travail consiste à transformer des données collectées pour d’autres fins en matériel de recherche pertinent pour les sciences sociales.
R et RStudio
- Essayez Positron
- VSCode
- VIM
- Cursor

Git et GitHub
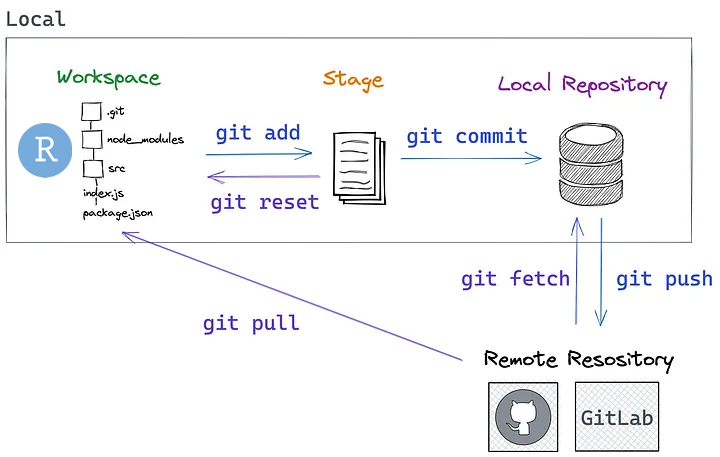
- Système de contrôle de version
- Suivi des modifications du code
- Historique complet du projet
- Branches pour développer en parallèle
Sondages et analyse d’enquêtes
- Conception de questionnaires
- Échantillonnage et représentativité
- Pondération des données
- Nettoyage et préparation
- Analyses statistiques descriptives et inférentielles
- Visualisation des résultats

Mesures latentes
- Variables non directement observables (attitudes, traits, opinions)
- Échelles multiples pour mesurer des concepts complexes
- Analyse factorielle pour identifier des structures sous-jacentes
- Création de variables composites
- Évaluation de la fiabilité et validité des mesures

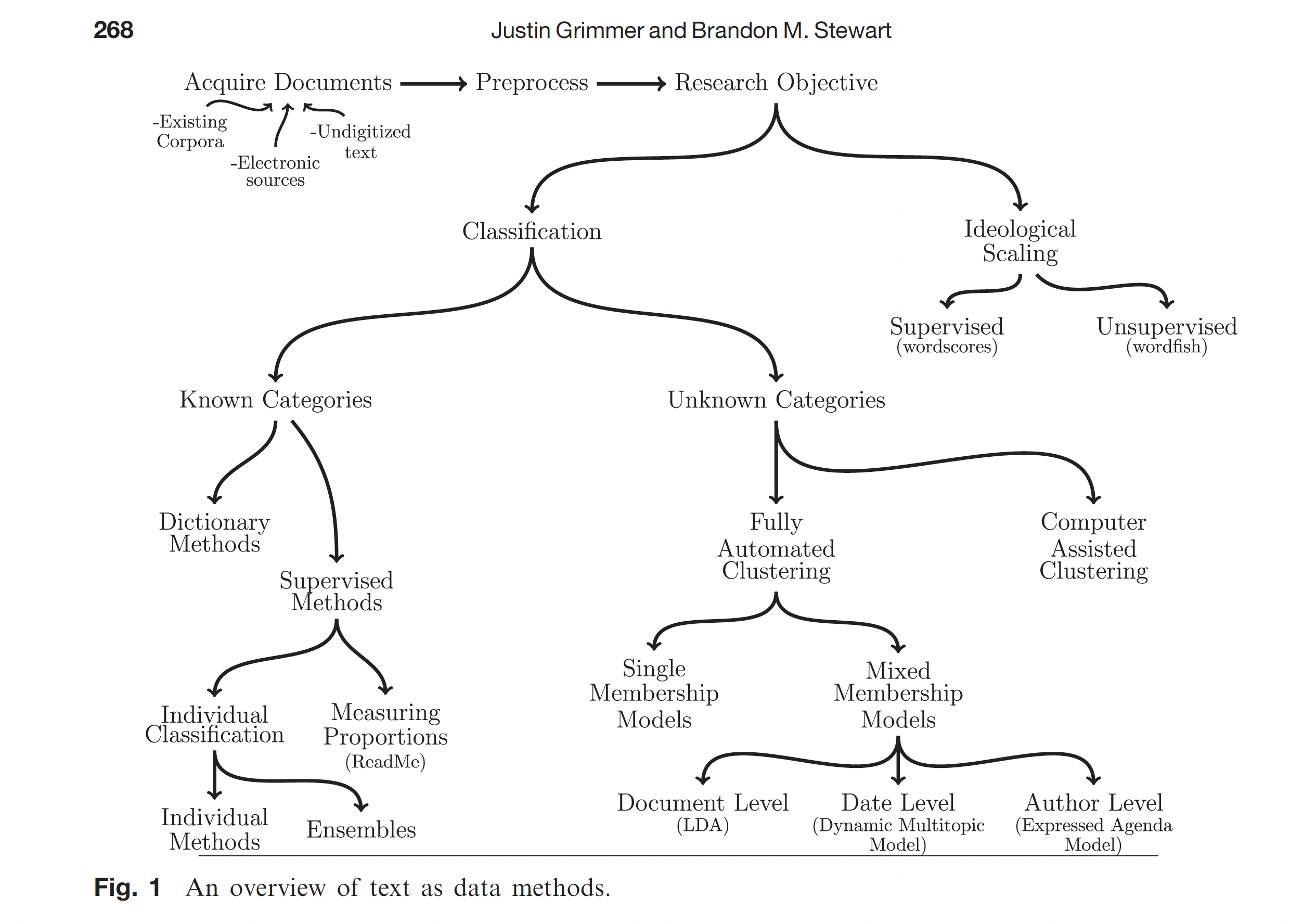
Analyse textuelle
- Prétraitement du texte (tokenisation, stemming…)
- Analyse de sentiments
- Modélisation de sujets (topic modeling)
- Classification de textes
Web scraping
- Extraction automatisée de données du web
- APIs pour accéder aux données structurées
- HTML parsing pour extraire des informations de sites web
- Considérations éthiques et légales
- Automatisation de la collecte
- Gestion et organisation des données extraites

Grands modèles linguistiques (LLM)
- IA entraînée sur d’énormes volumes de texte
- Capacités de génération et compréhension du texte
- Applications en sciences sociales:
- Classification de textes
- Analyse de sentiment
- Codage qualitatif assisté
- Enjeux éthiques:
- Biais algorithmiques
- Confidentialité des données
- Fiabilité des résultats
- Besoin de validation humaine

Analyse d’images
- Traitement d’images à grande échelle
- Reconnaissance d’objets et classification
- Analyse de représentations médiatiques
- Computer vision et réseaux de neurones
- Applications en sciences sociales:
- Analyse de couverture médiatique
- Étude des représentations sociales
- Mesure de la diversité et de l’inclusion

Merci
![]()