flowchart LR
A[Ingrédients<br/>Arguments] -->|Entrée| B(La Machine<br/>Fonction)
B -->|Traitement| C[Résultat<br/>Output]
style A fill:#e74c3c,stroke:#333,stroke-width:2px,color:white
style B fill:#3498db,stroke:#333,stroke-width:2px,color:white
style C fill:#2ecc71,stroke:#333,stroke-width:2px,color:white
Introduction à R
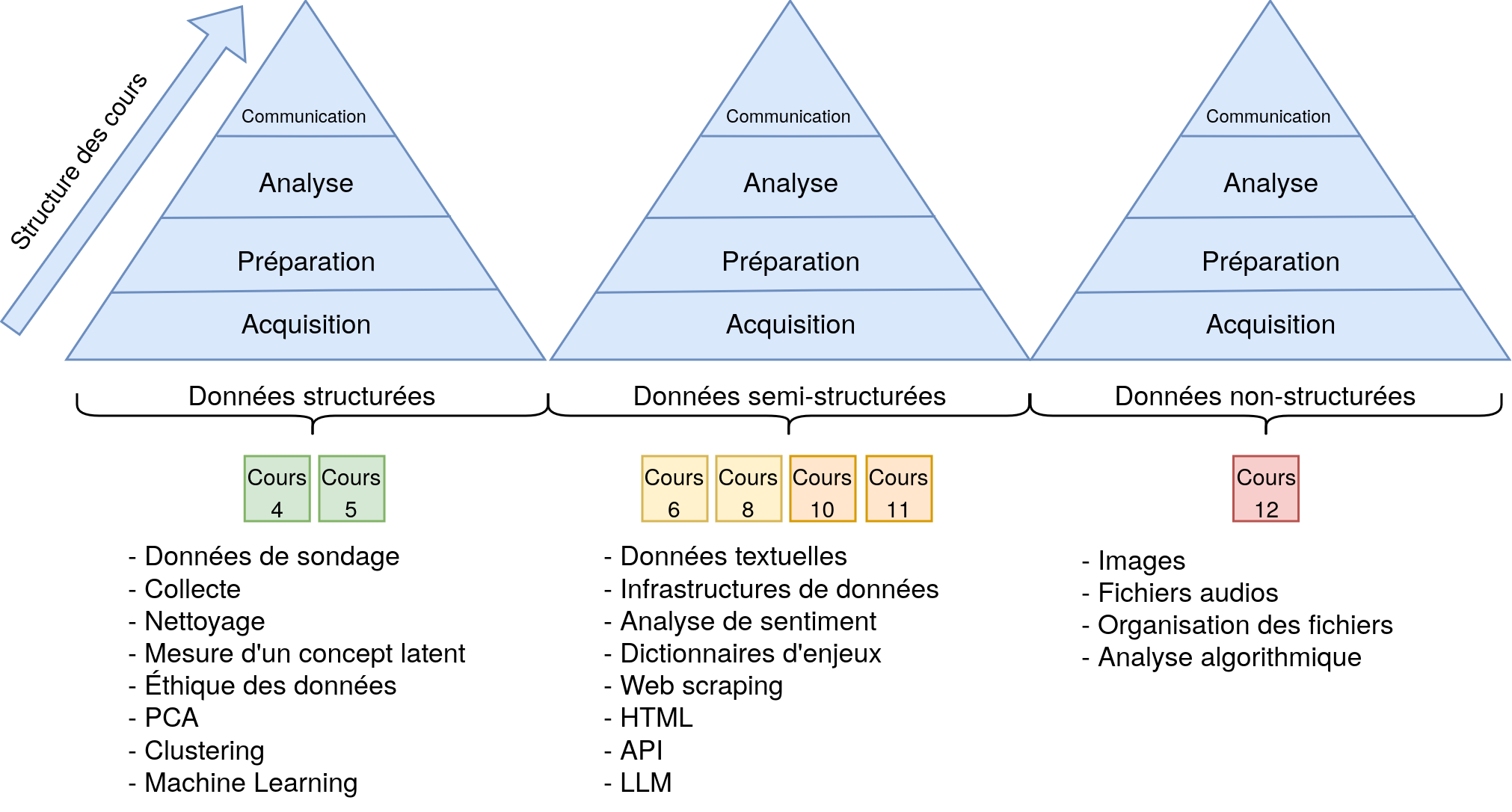
Introduction aux mégadonnées en sciences sociales
Structure du cours
Les outils pour y arriver
Les outils d’analyse de données
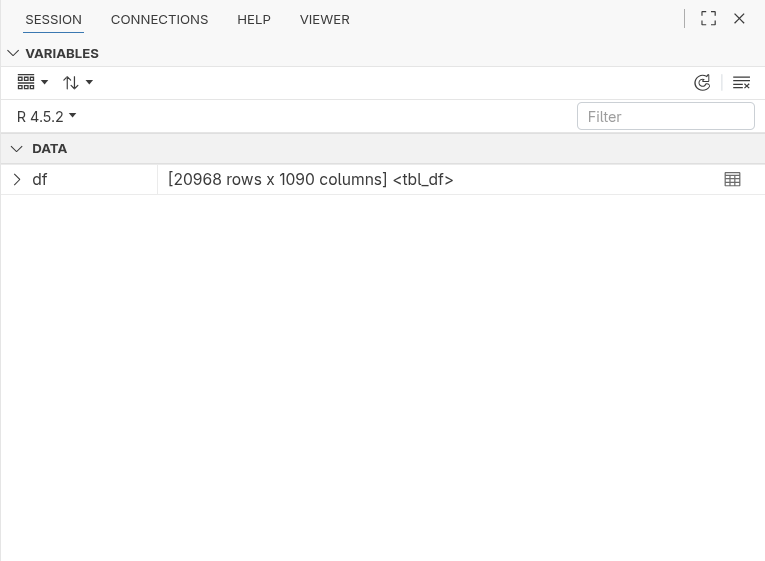
![]()
![]()
![]()
![]()
![]()
Pourquoi R?
![]()
Open source
- Gratuit
- Collaboratif
- Communauté active
- Adapté aux besoins des utilisateurs
Pourquoi R?
![]()
Packages
- Offre une extension des fonctionnalités de base presque infinie
- Peux répondre à des besoins très spécifiques
- Plus de 22,000 packages sur CRAN (Comprehensive R Archive Network)
- Beaucoup plus sur GitHub
Pourquoi R?
![]()
Tidyverse
Collection de packages pour la manipulation de données
dplyr: manipulation de donnéesggplot2: graphiquestidyr: nettoyage de donnéesreadr: importation de donnéesstringr: manipulation de chaînes de caractères
Pourquoi R?
![]()
Packages CLESSN
- sondr
- Permet l’automatisation de plusieurs aspects de l’analyse de données. Nous permet de faire des analyses factorielles en quelques secondes.
- clellm
- Permet d’utiliser des LLM open-source directement en R et permet d’utiliser des fonctions disponibles seulement en Python, en R.
- clessnize
- Permet de standardiser le style de nos graphiques rapidement sans avoir à répéter les mêmes étapes à chaque fois.
Pourquoi R?
![]()
Reproductibilité
- Rendre les analyses reproductibles
- Permet de partager le code
- Facilite la transparence et la collaboration
- Permet de retracer les erreurs
Pourquoi R?
![]()
Très utilisé en science sociale
- Beaucoup de ressources
- Beaucoup de tutoriels orientés vers les sciences sociales
- Swirl
- Datacamp
- Codecademy
Important d’utiliser les mêmes outils que les chercheurs dans votre domaine
Pourquoi R?
![]()
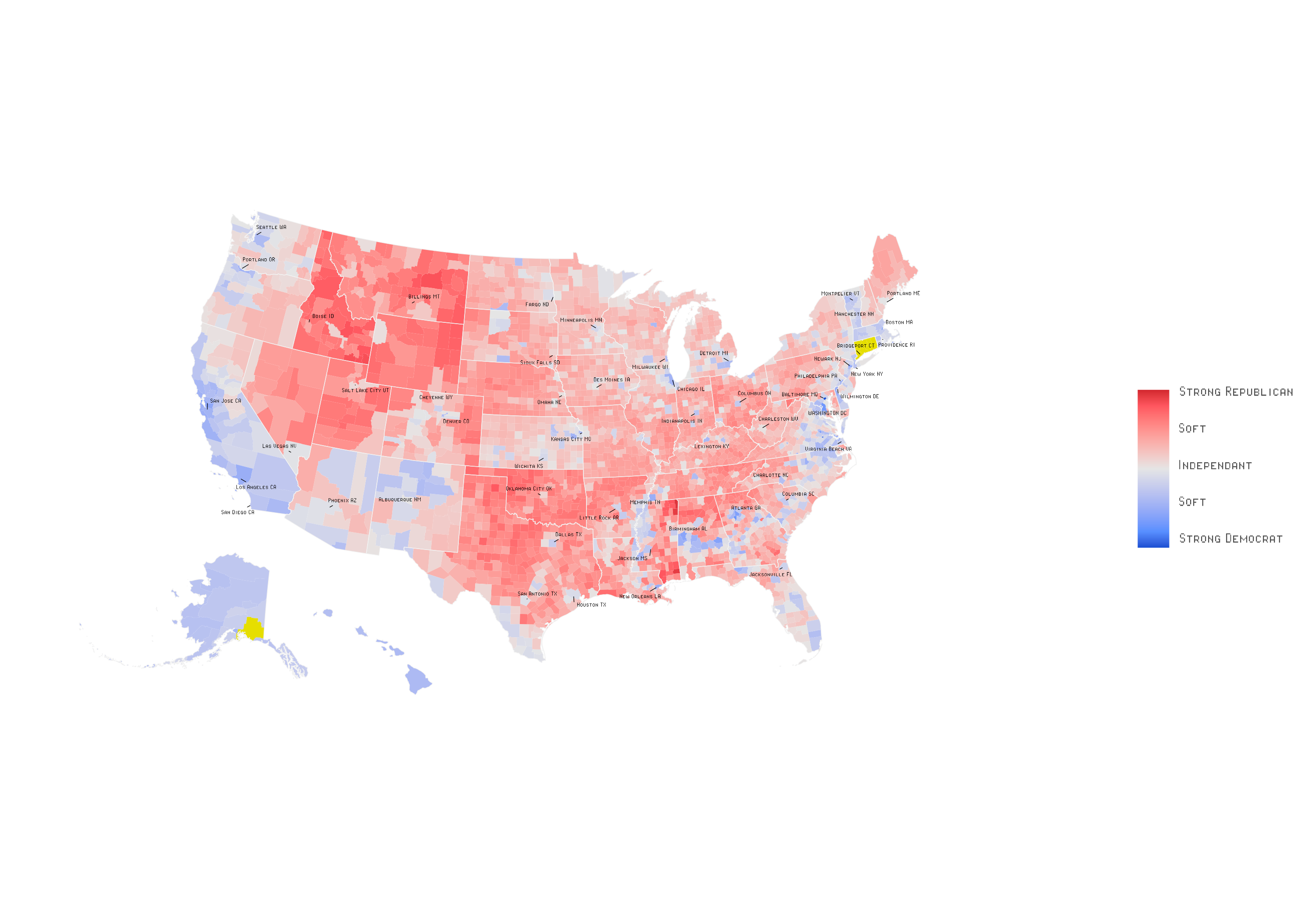
Exemples d’utilisation par des organisations

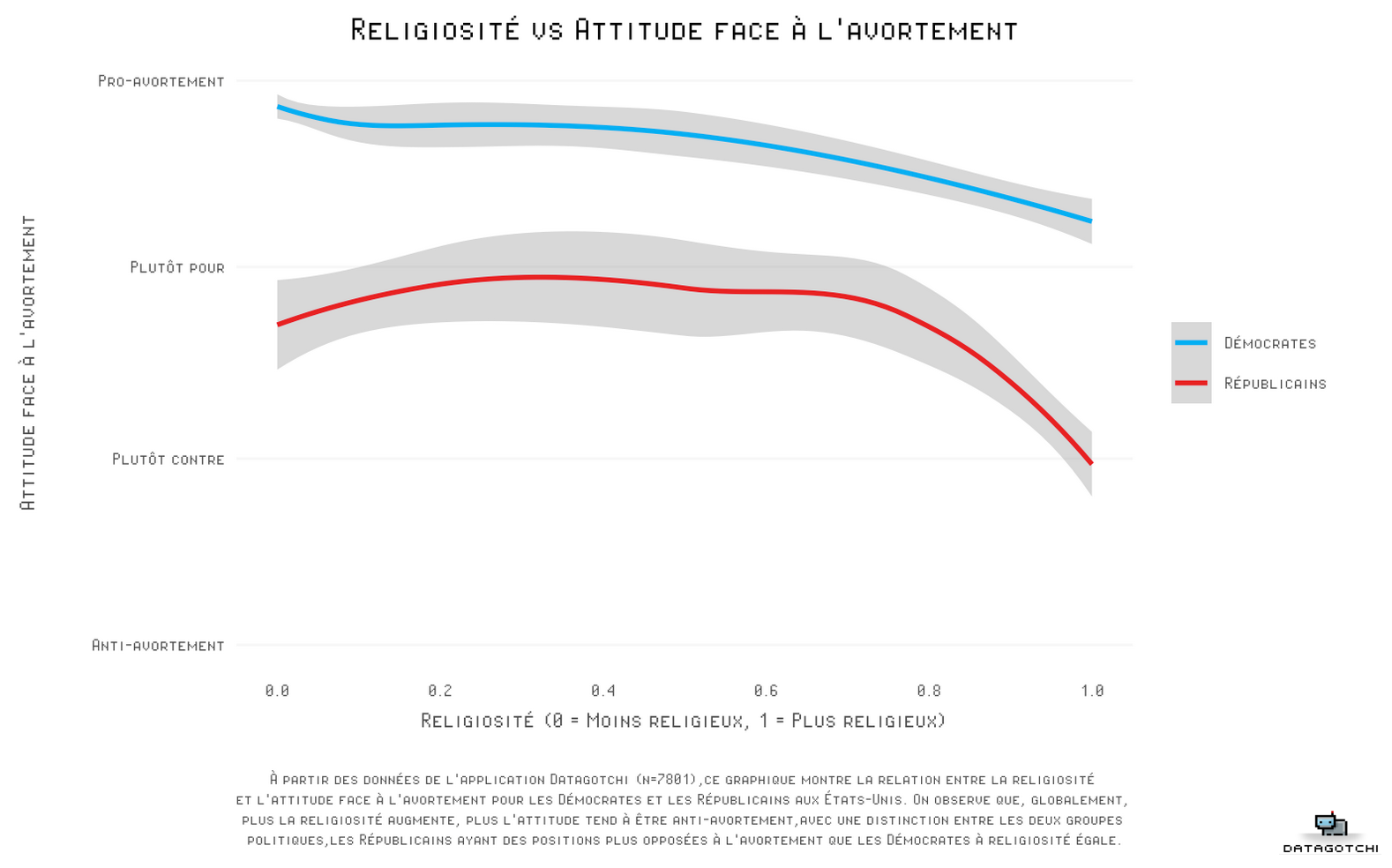

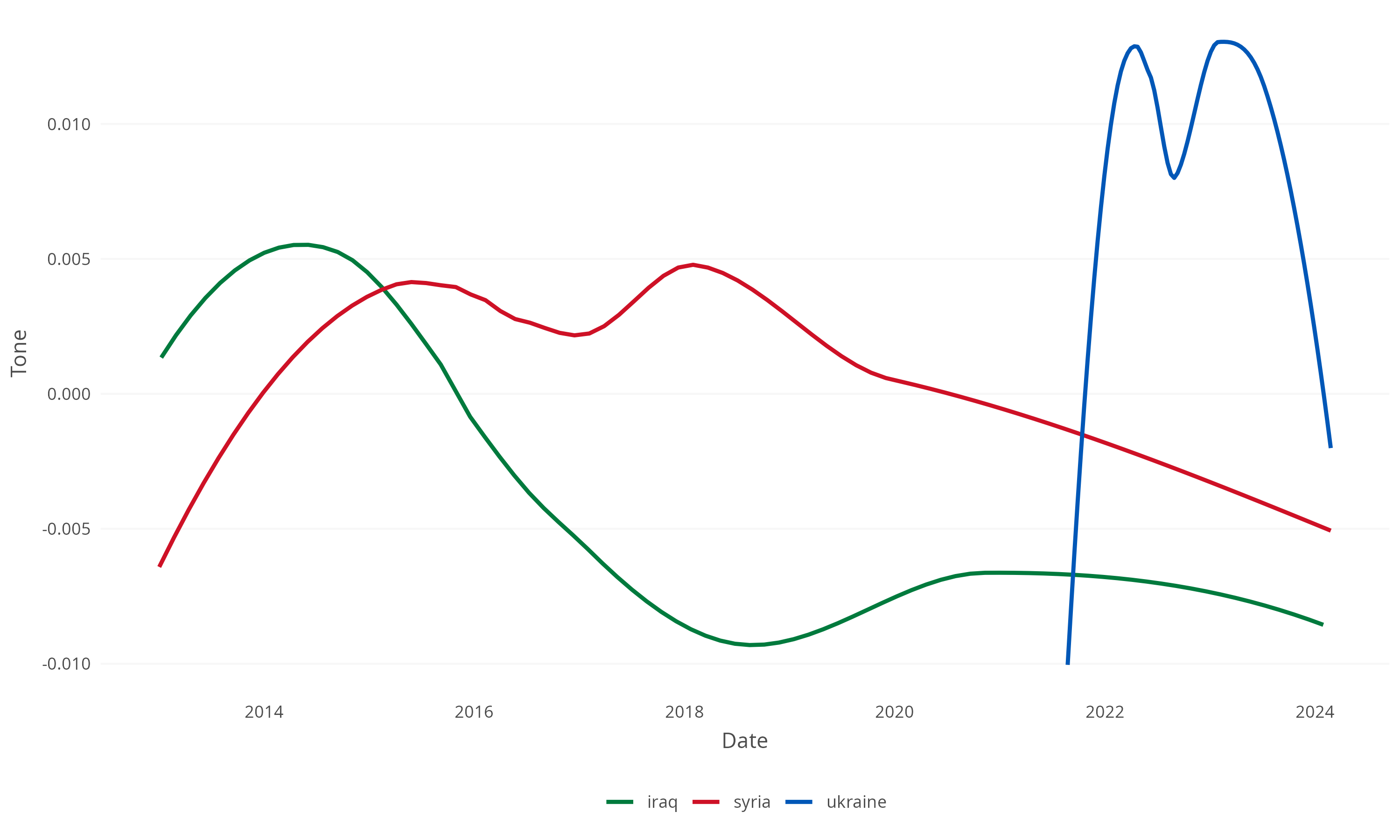
Analyse textuelle
- Analyse de ton
R : Au-delà de l’analyse de données
- R ne se limite pas à l’analyse statistique, il peut aussi être utilisé pour développer des applications web interactives
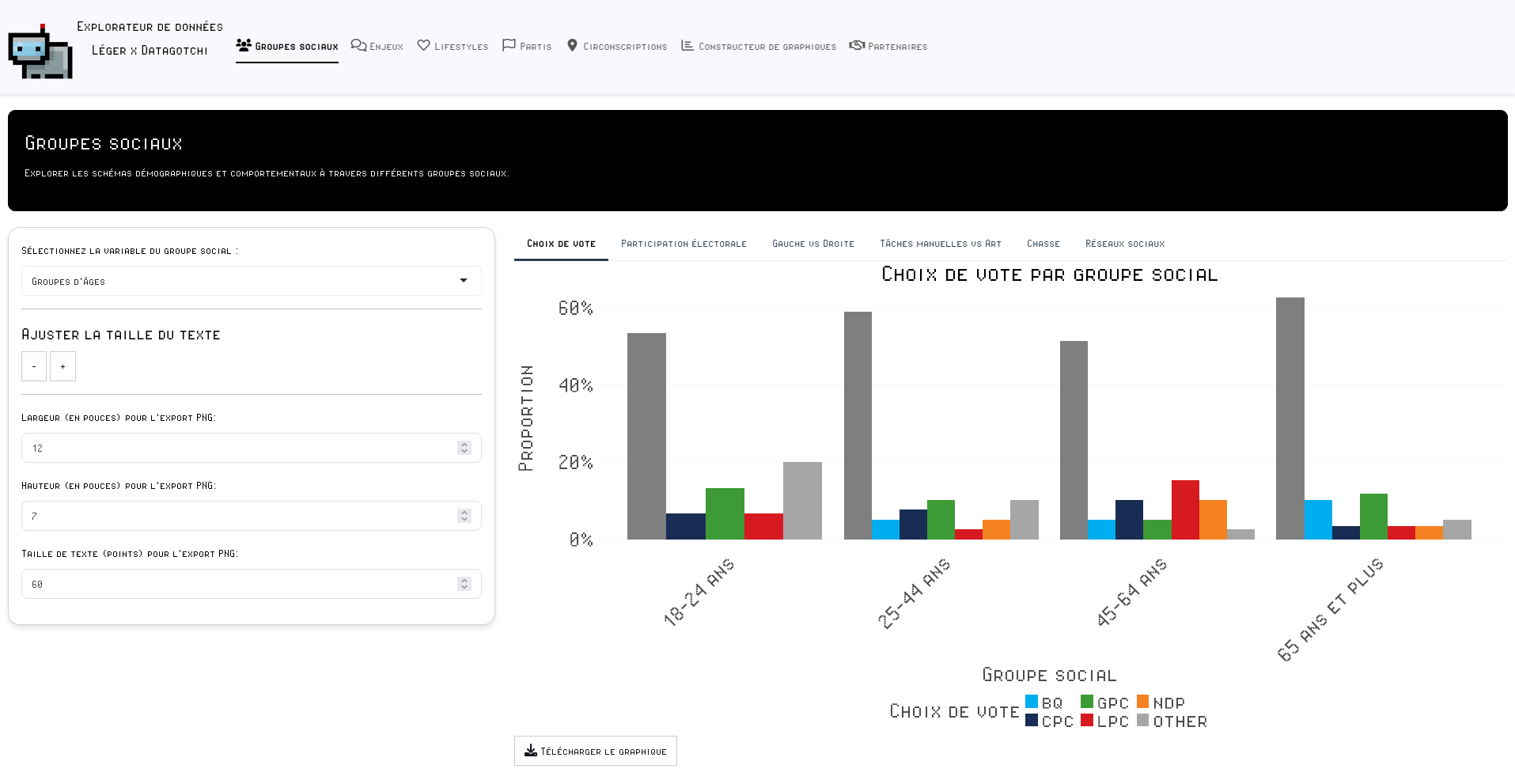
Avant de commencer : Le chemin d’arborescence
- À tout moment vous devez savoir où vous êtes dans votre ordinateur
- Votre R « pointe » toujours vers un dossier de votre ordinateur
- C’est le répertoire de travail (working directory)
- La fonction
getwd()permet de connaitre le répertoire de travail actuel
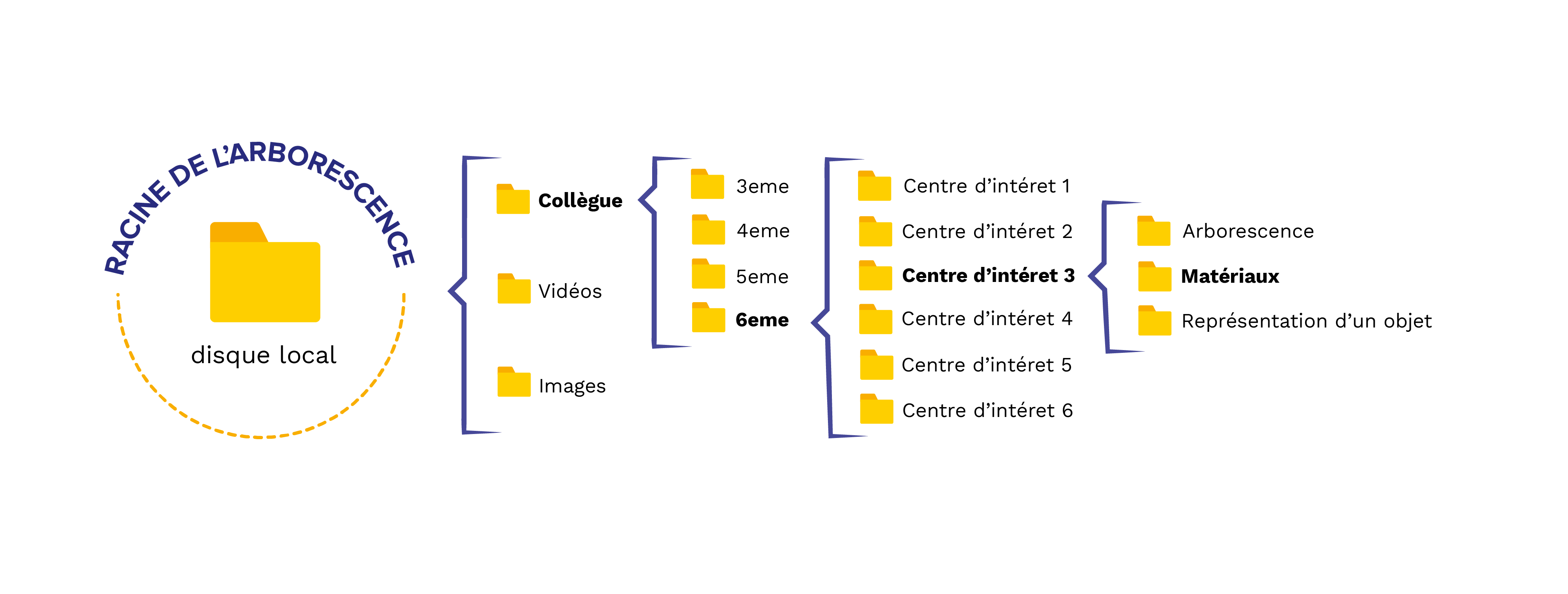
~/Collègue/6eme/Centre d’intéret 3/Matériaux/
Avant de commencer : Le chemin d’arborescence
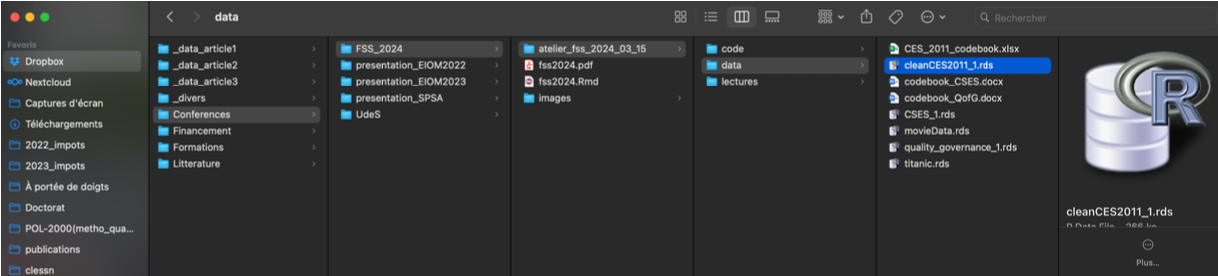
Importer des données
Autres fonctions pour importer des données dépendamment du format:
df <- readxl::read_excel("chemin/vers/data.xlsx")df <- readRDS("chemin/vers/data.rds")df <- haven::read_sav("chemin/vers/data.sav")