



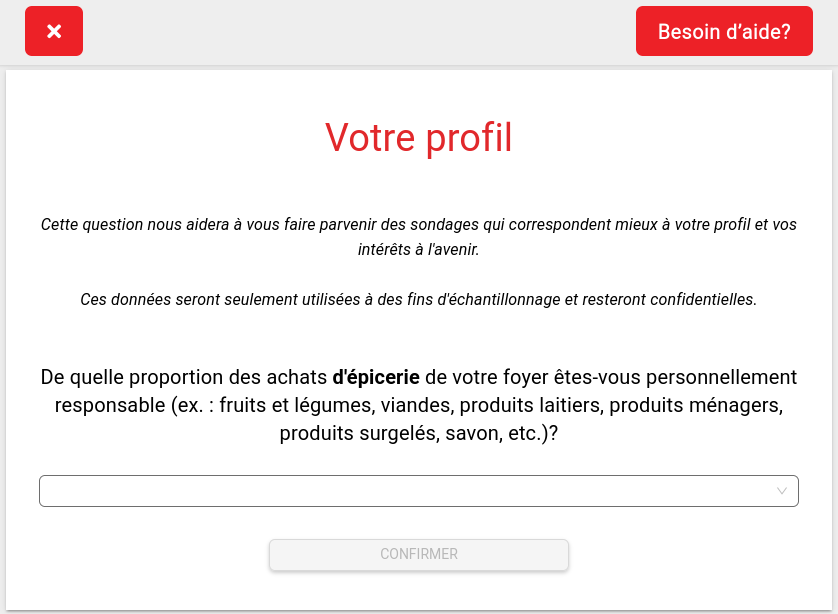
Maintenant: L’ère comportementale (2010+)
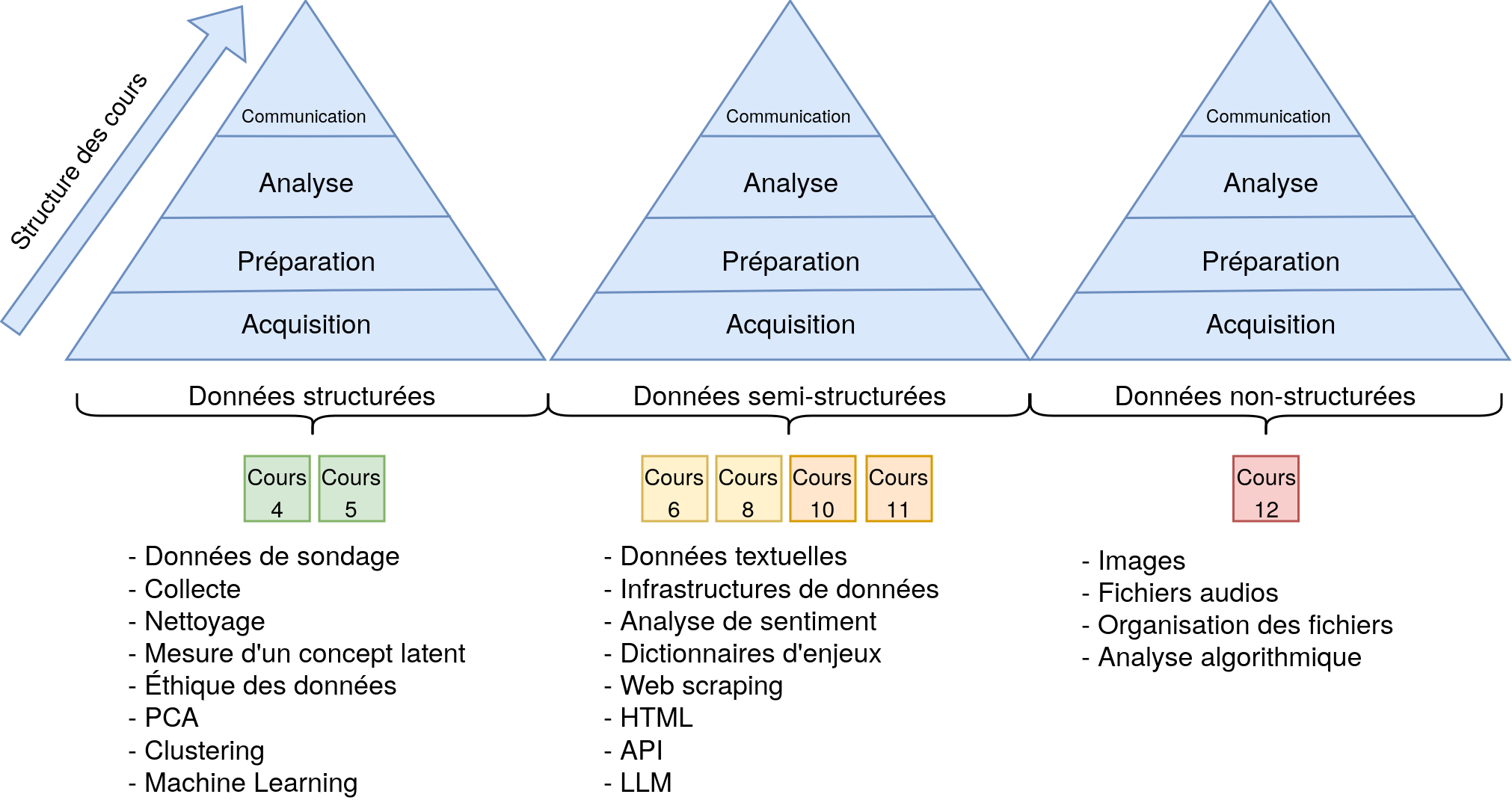
La “Dataification”
- Paradigme : On ne pose plus de questions, on observe.
- Collecte : Passive (GPS, Clics, Transactions, Réseaux sociaux).
- Risque : Données collectées et utilisées sans consentement.
- Futur : Hybridation (Sondages + Traces numériques).

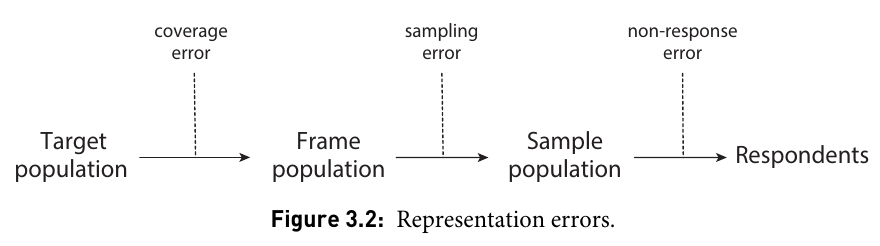


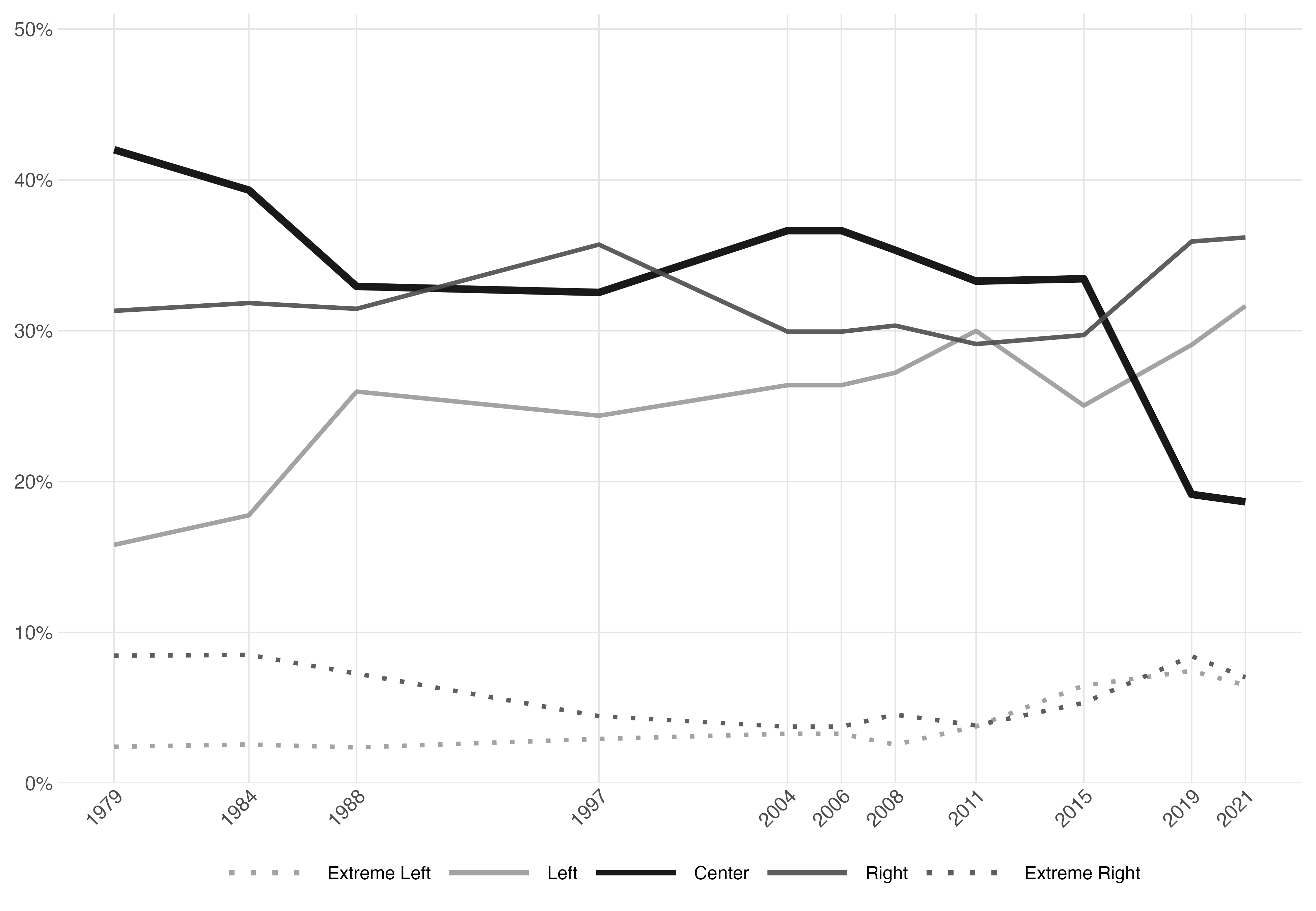
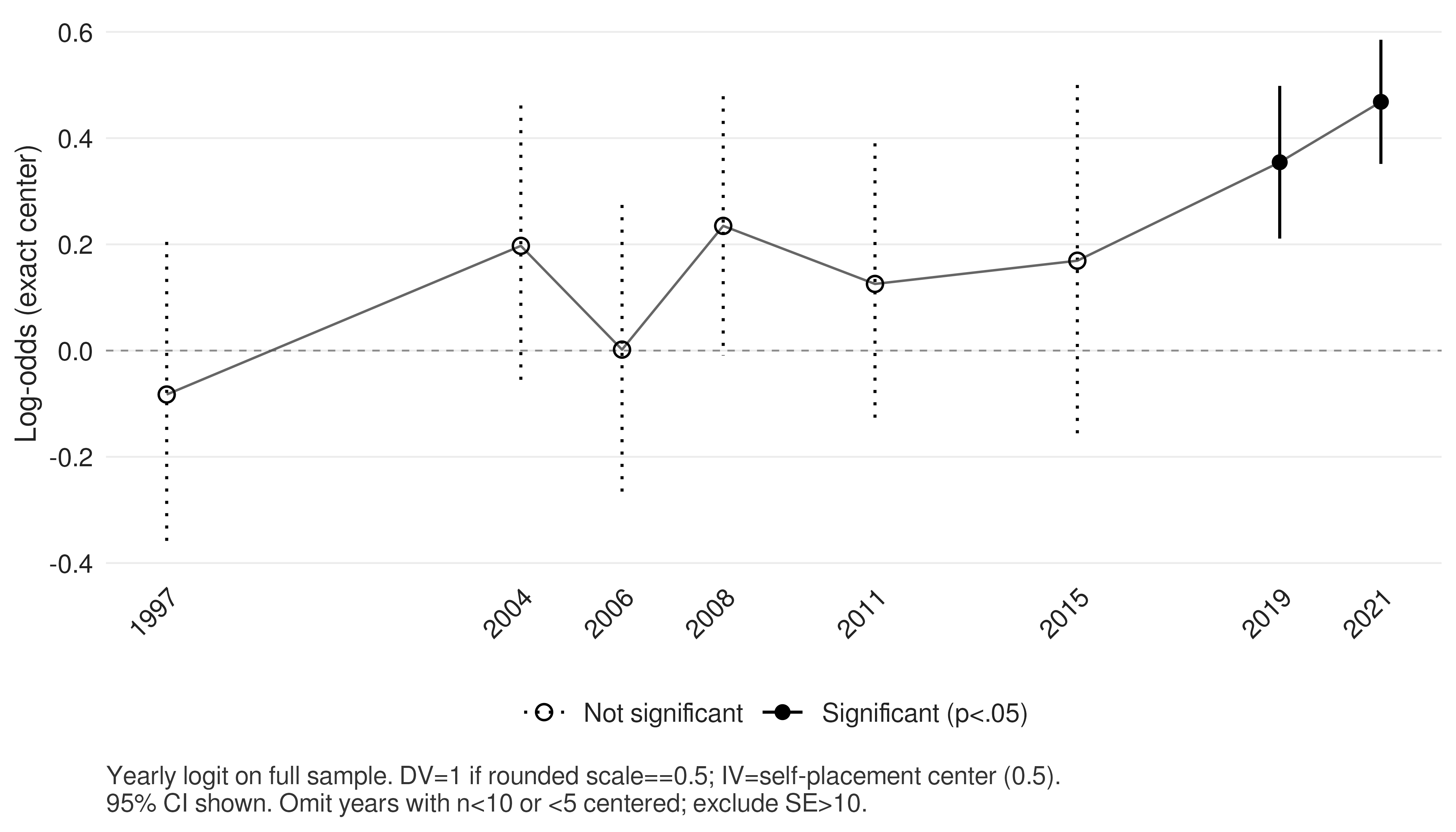
Comment pondérer?
La formule de base
Pour notre exemple
En pratique