Les mesures et les analyses statistiques
Introduction aux mégadonnées en sciences sociales
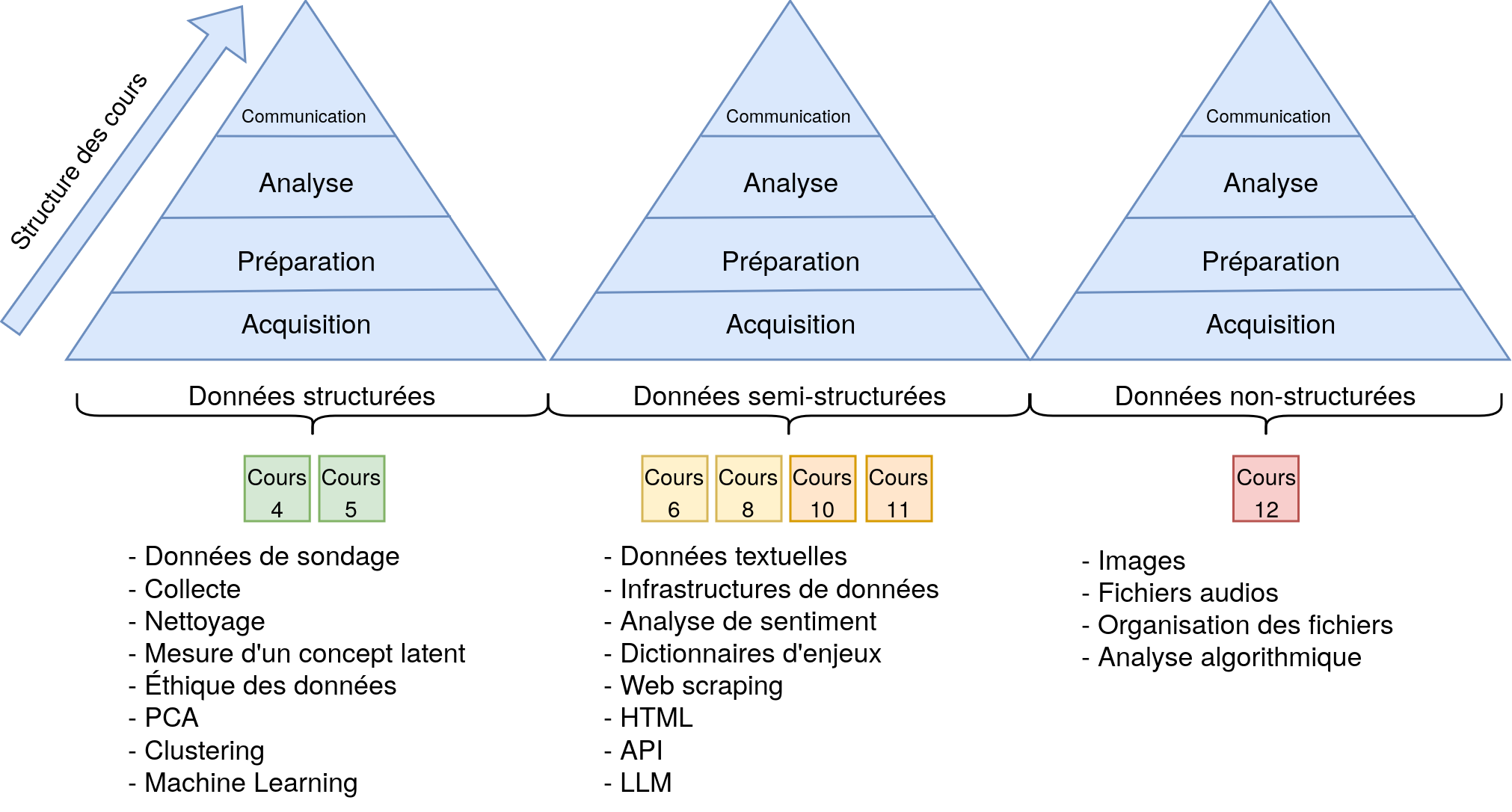
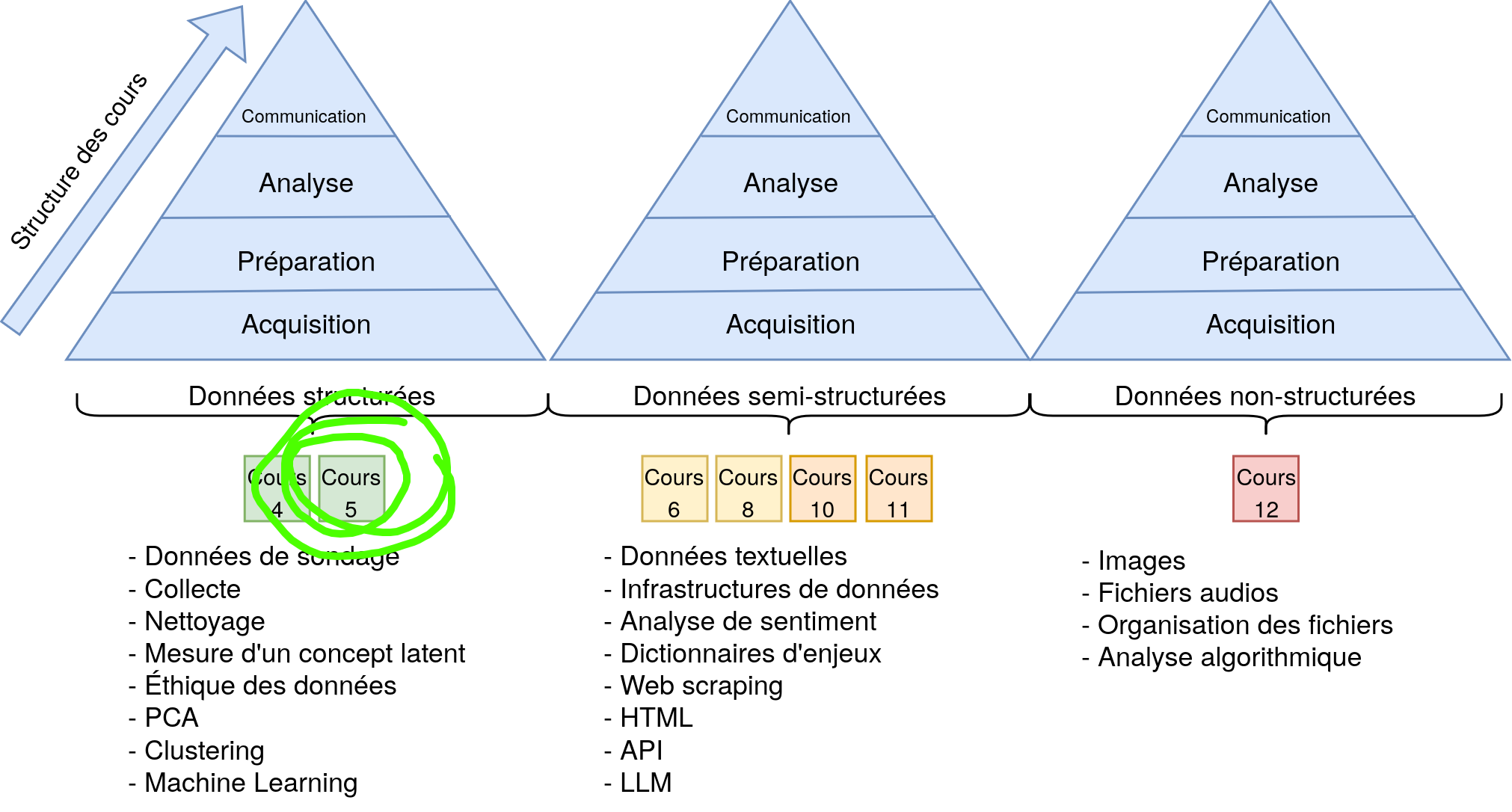
Structure du cours
Exemple : Mesurer l’intelligence

échelle de l’attitude politique

échelle de l’attitude politique

échelle de l’attitude politique

échelle de l’attitude politique

L’échelle d’idéologie de Merkley (2022)

Les 8 questions de l’étude (Merkley, 2022)

Solution : Les échelles de mesure
Comment procéder?
- Identifier les dimensions clés
- Décomposer le concept
- Définir les aspects mesurables
- Créer des indicateurs
- Questions précises
- Observations concrètes
- Valider l’échelle
- Fiabilité : Tests statistiques
- Validité : Théorique

Critères essentiels

Critères essentiels

Critères essentiels

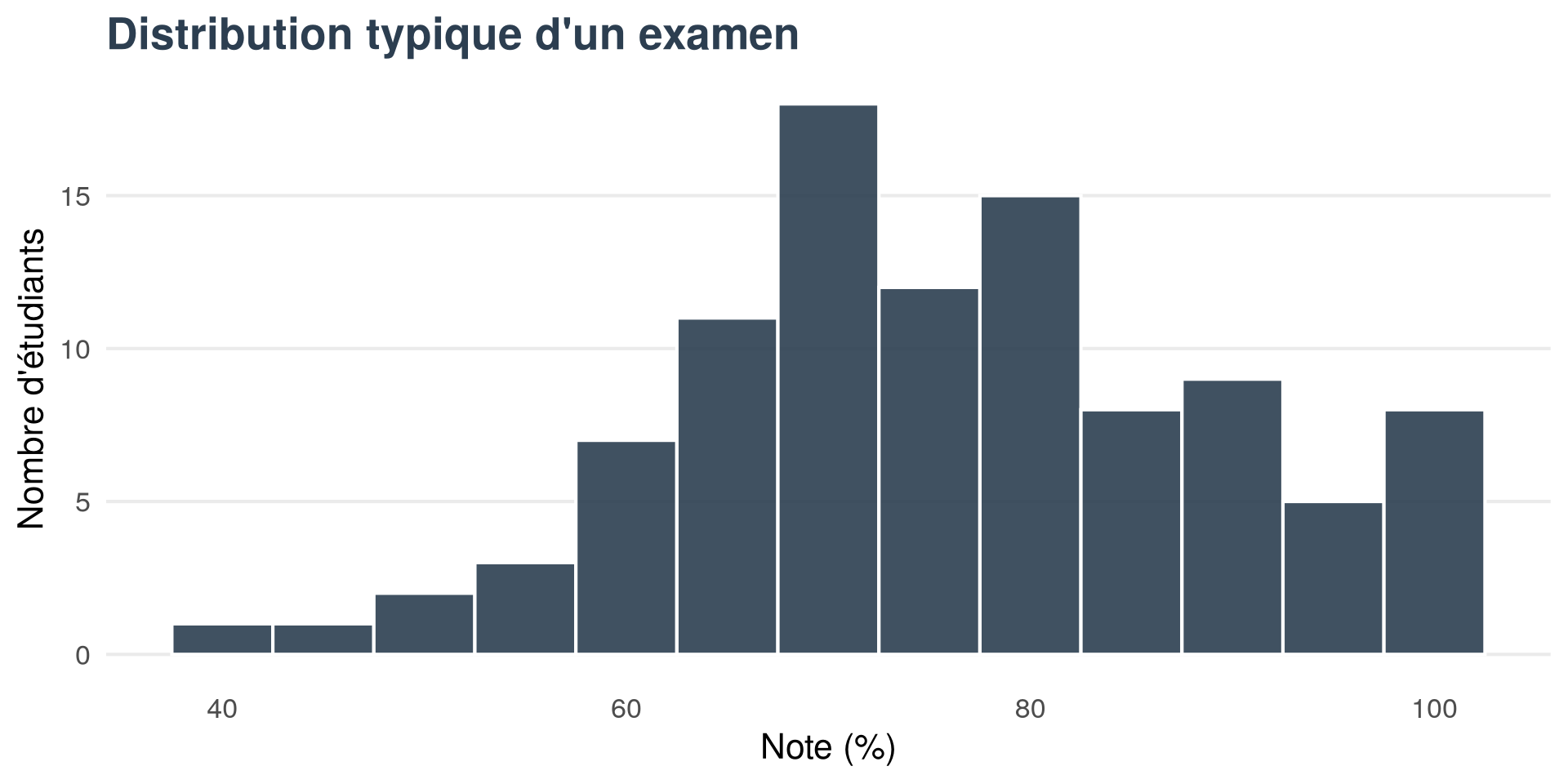
Examen d’histoire

Distribution typique d’un examen
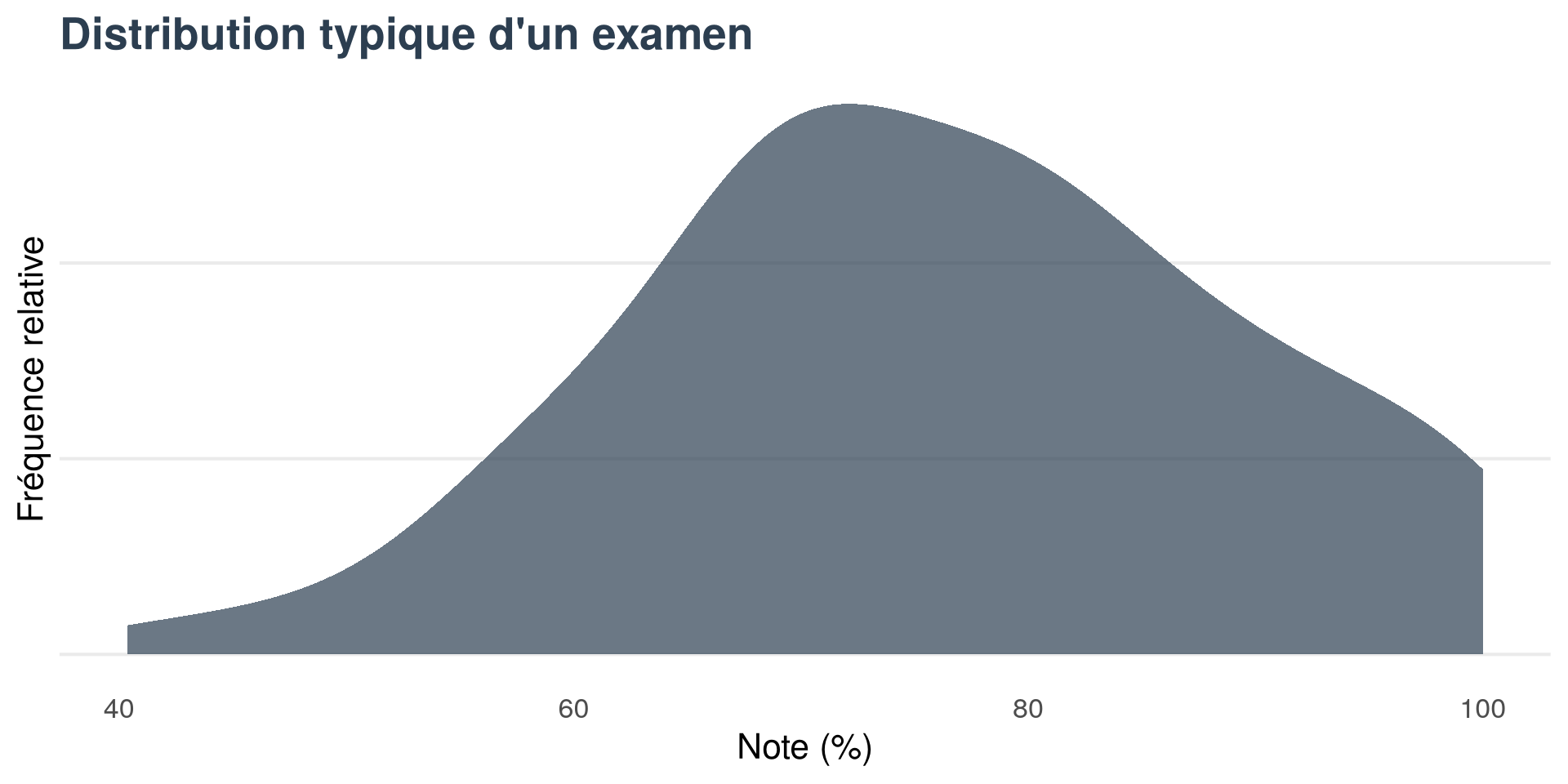
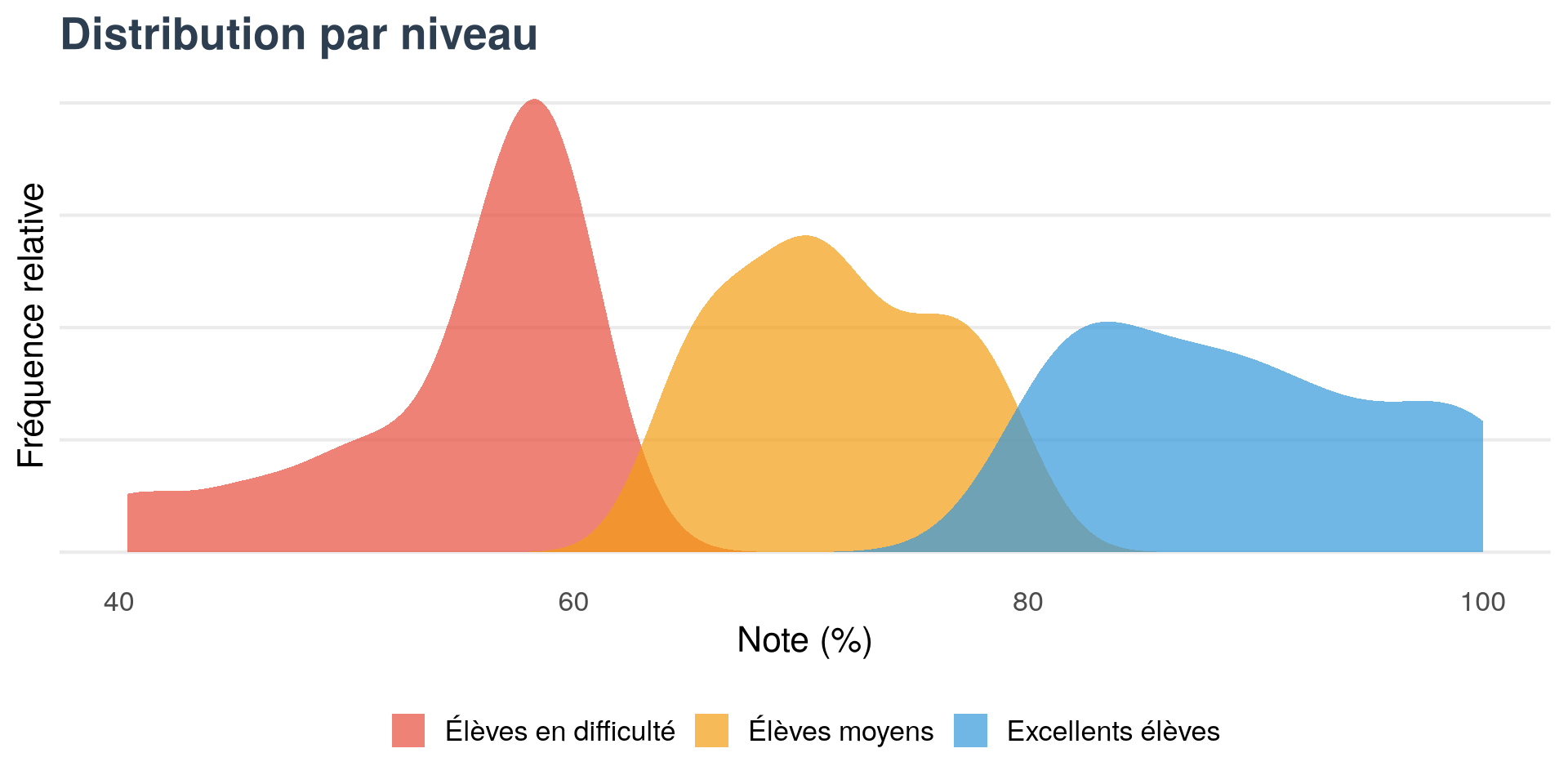
Distribution par groupes d’élèves
Question 1 : Causes de la guerre
“Quels événements ont directement mené au déclenchement de la Seconde Guerre Mondiale en Europe?”

Question 2 : Analyse stratégique
“Expliquez pourquoi l’opération Barbarossa a été un tournant décisif dans la guerre.”

Question 3 : Impact économique
“Analysez comment la mobilisation industrielle des États-Unis a influencé l’issue de la guerre.”

Question 4 : Conséquences géopolitiques
“Évaluez comment les accord de Yalta ont redessiné la carte politique de l’Europe.”

Question 5 : Cigares de Churchill
“Quelle était la marque de cigares préférée de Winston Churchill?”

L’analyse factorielle compare toutes les questions

Comment faire ?

Comment faire ?

df$scale_redneck

Les composants de base

Visualisation avec ggplot2

Visualisation avec ggplot2
Ajouter un geom_()
- Il existe plusieurs
geom_()pour différents types de graphiquesgeom_point()pour un nuage de pointsgeom_line()pour un graphique linéairegeom_bar()pour un graphique à barresgeom_histogram()pour un histogramme
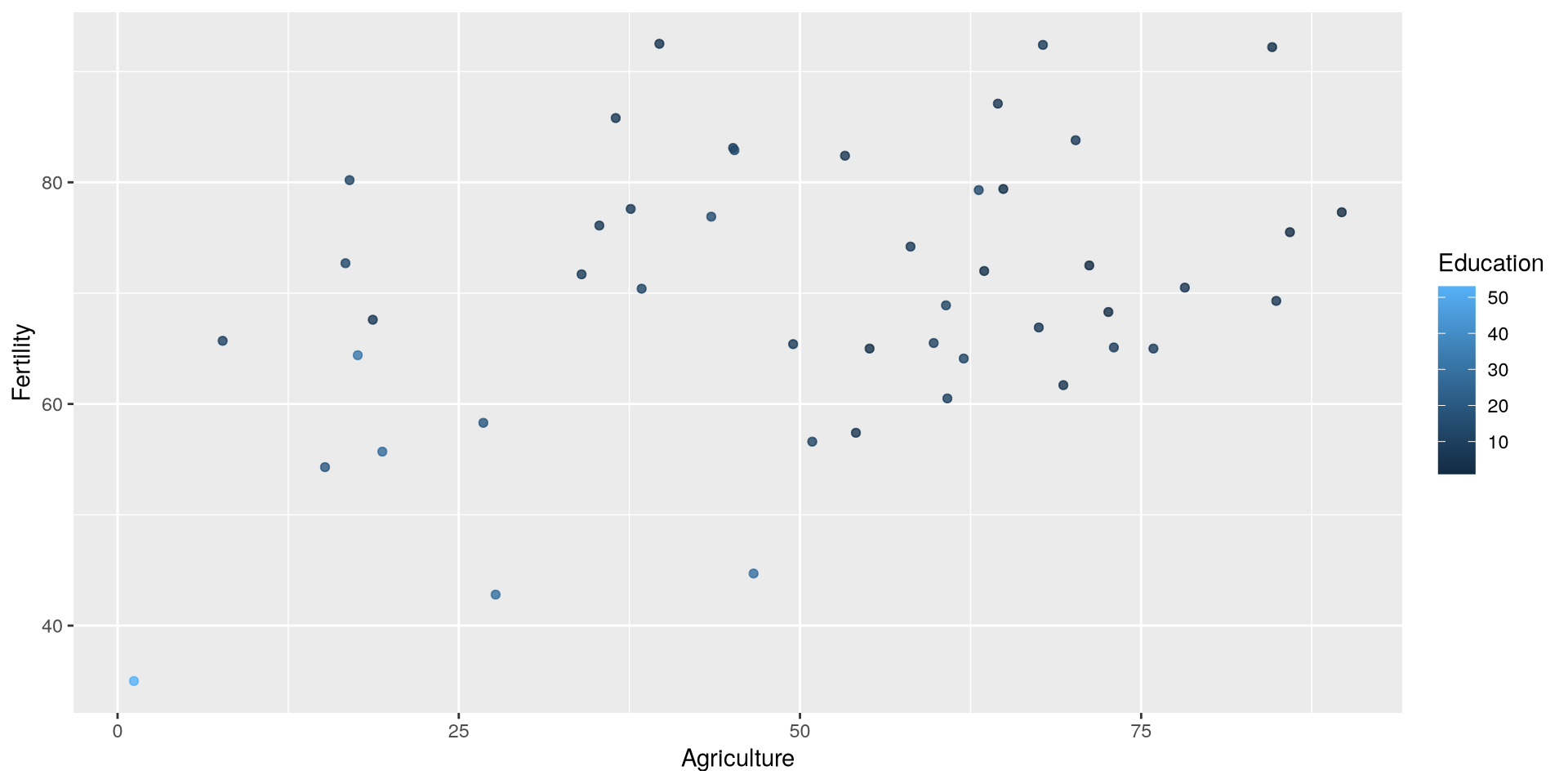
Visualisation avec ggplot2
Ajouter une échelle de couleur
scale_color_gradient()permet de spécifier les couleurs pour la variableEducationlowethighsont les couleurs pour les valeurs les plus basses et les plus hautesnameest le nom de la légende- Vous pouvez utiliser les hexcodes pour les couleurs
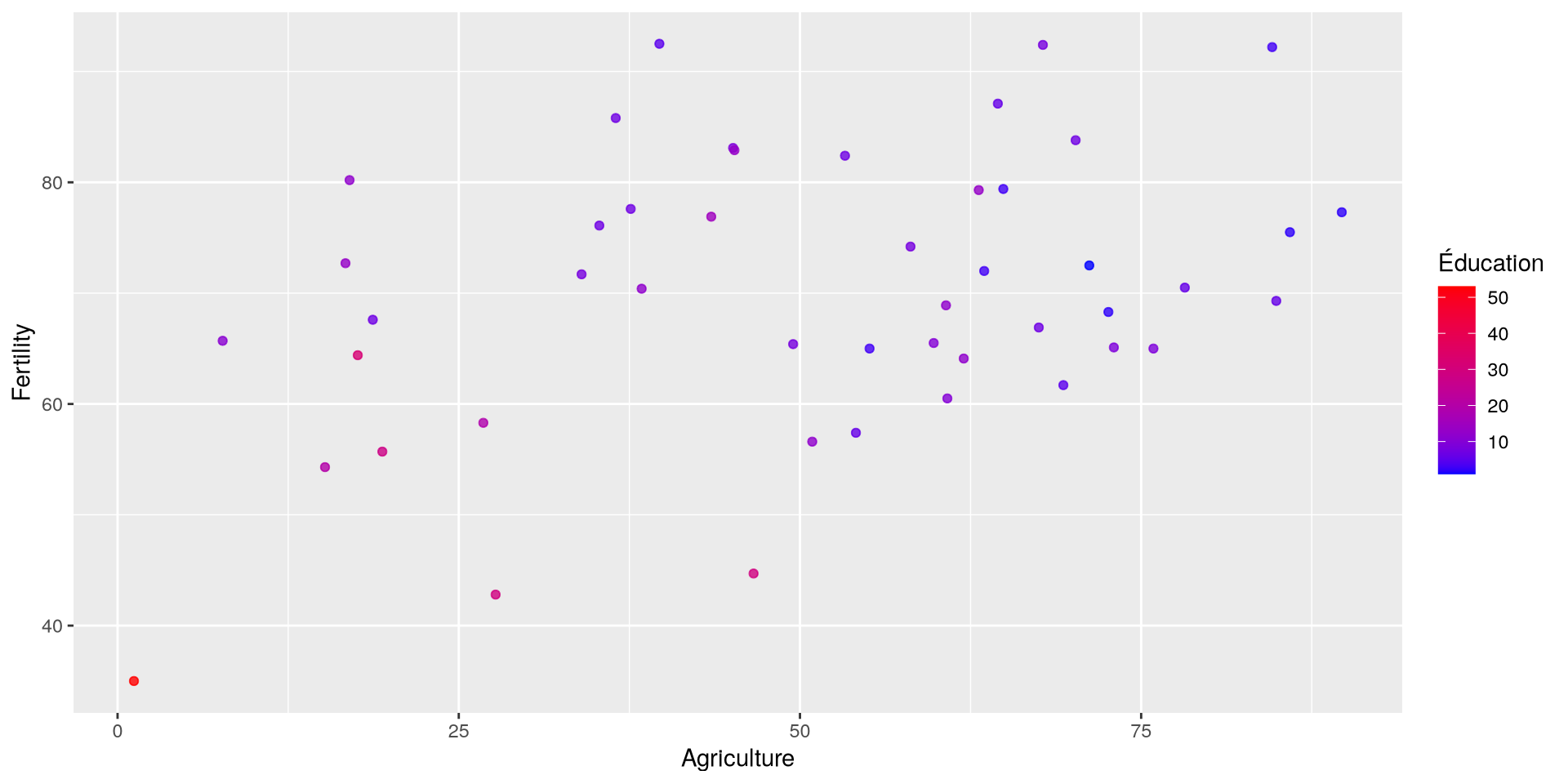
Visualisation avec ggplot2
Ajouter des titres et des labels
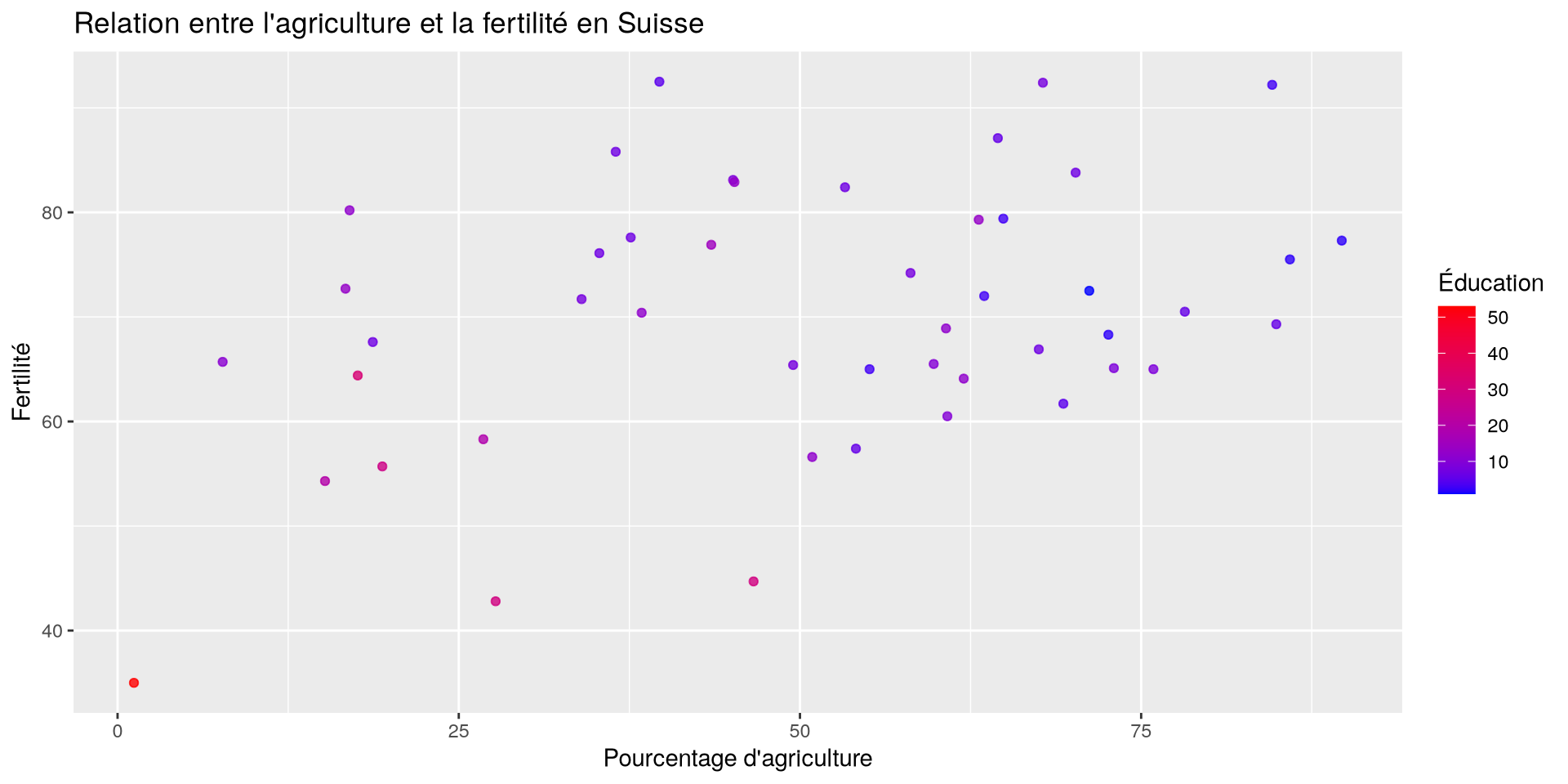
ggplot(df, aes(x = Agriculture, y = Fertility, color = Education)) +
geom_point(alpha = 0.8) + # Le alpha est la transparence
scale_color_gradient(low = "blue", high = "red", name = "Éducation") +
labs(
title = "Relation entre l'agriculture et la fertilité en Suisse",
x = "Pourcentage d'agriculture",
y = "Fertilité"
) 
Visualisation avec ggplot2
Ajouter un thème
ggplot(df, aes(x = Agriculture, y = Fertility, color = Education)) +
geom_point(alpha = 0.8) + # Le alpha est la transparence
scale_color_gradient(low = "blue", high = "red", name = "Éducation") +
labs(
title = "Relation entre l'agriculture et la fertilité en Suisse",
x = "Pourcentage d'agriculture",
y = "Fertilité"
) +
theme_minimal()theme_minimal()est un thème minimaliste- Il existe plusieurs thèmes prédéfinis dans ggplot2
- Vous pouvez aussi créer votre propre thème
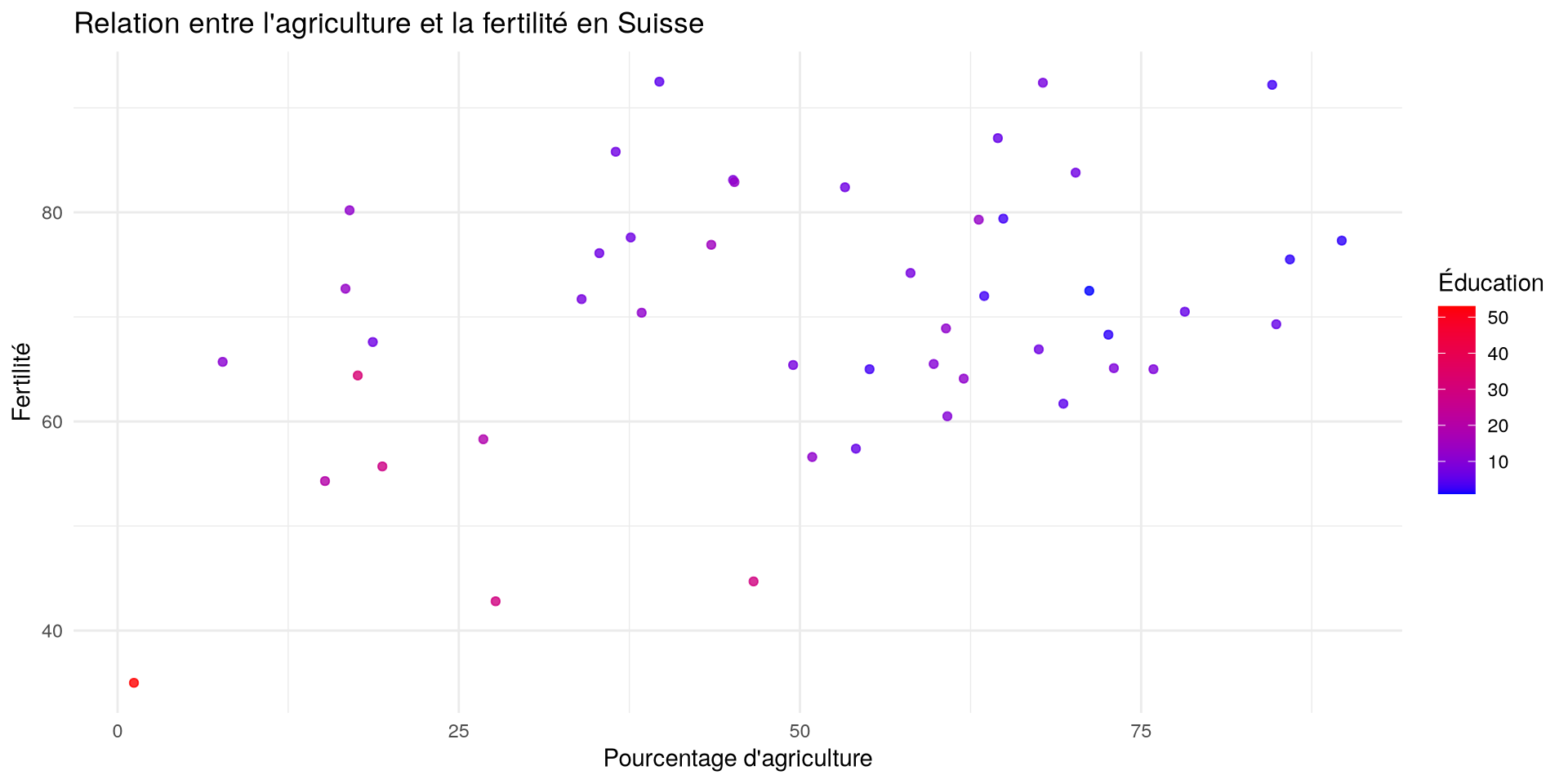
Visualisation avec ggplot2
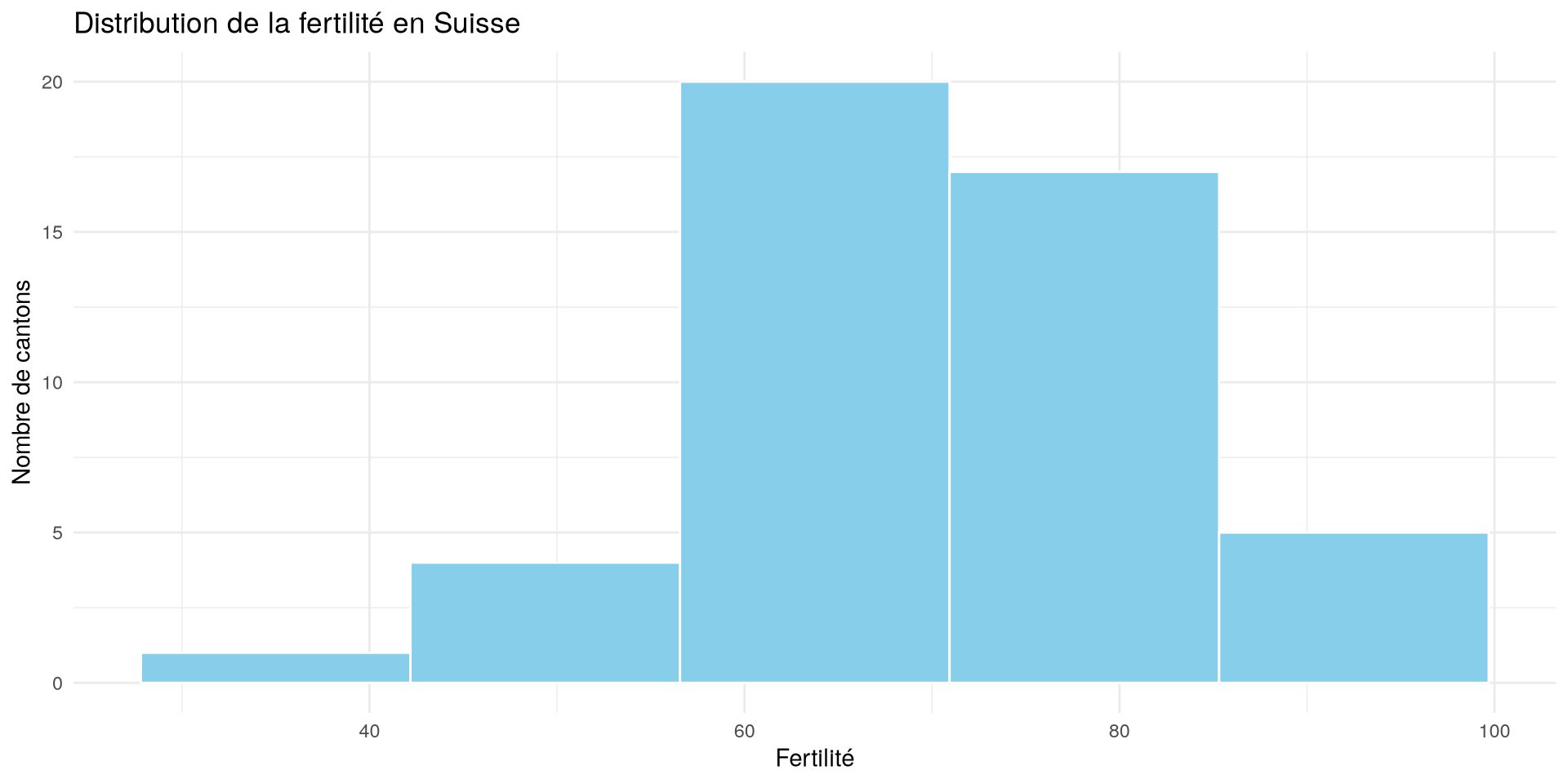
Un histogramme de la variable Fertility
Visualisation de la régression

Comment ça marche?

Comment ça marche?

Comment ça marche?














Comment ça marche?
L’analyse factorielle vérifie
Nos résultats